In the last fortnight for Semester 1, we learned about Algorithm and Machine Learning (ML). One of my favourite moments this fortnight was when we were asked to train the cups as our agents to beat us in a NIM game. I never played that game before, and to learn that I just taught my cup agents to beat me and my partner (Sarah), was a mind-blowing moment for me. It’s incredible how a simple game can help me understand the simple machine learning concept, particularly reinforcement learning with repetition and algorithm. There’re some pattern and formula that I can see at the end of the game. This learning through play is excellent, and this is how I want my children to learn in life. The joy of learning, the excitement of challenges, and the fun of discovering something new or even something about myself has genuinely mesmerised me.
My motivation to learn machine learning skill this year is because I find machine learning to be a fascinating field. I would like to understand what’s going on behind the decision that often machines made about our daily life. How the machine learn pattern through the dataset that we (human) collected, train, test and build a model, and everything else in between. My learning goal is to understand when to use, which model to use to solve what problem, how to create and integrate a machine learning model into a cyber-physical system that is inclusive, fair and unbiased. I want to be comfortable to use the TensorFlow and Teachable Machines.
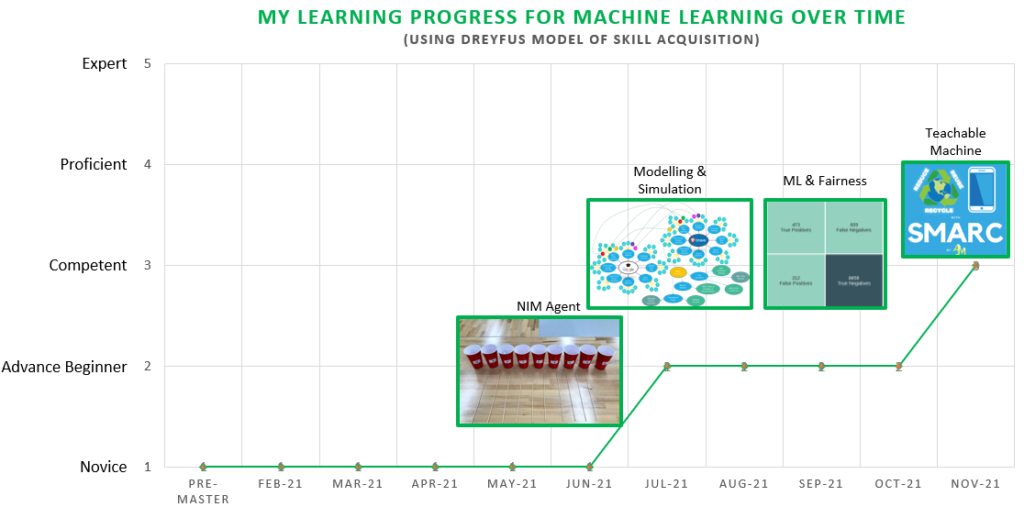
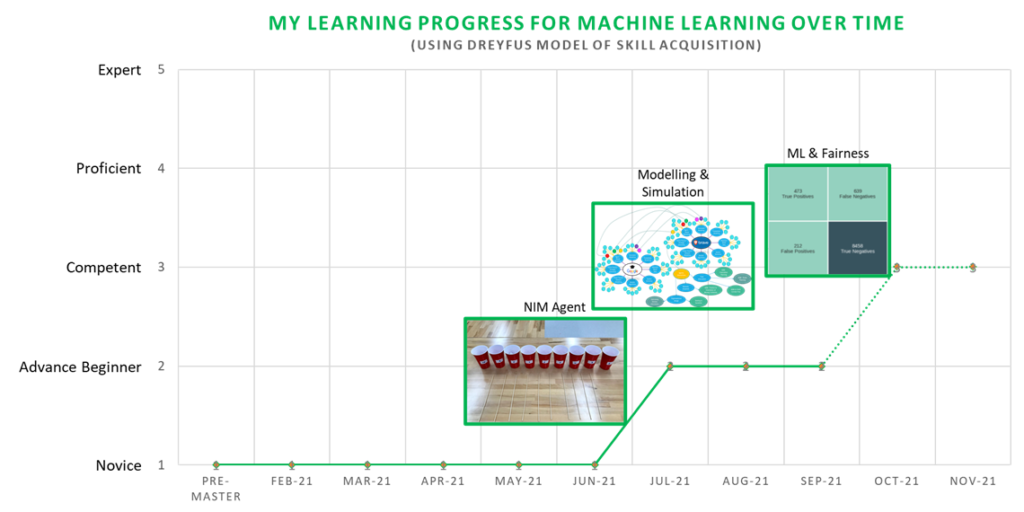
Overall, based on the Dreyfus Model of Skill Acquisition, and the Build homework for the last 3 fortnights (introduction to Scikit-learn and the ML Pipeline, Modelling & Simulation, and the ML & Fairness), I would categorise my current understanding of Machine Learning as Advance Novice to Beginner level now, moving from having zero experience (Novice level) before pre-master up until end of Semester 1. I know that the best way to improve for me is to continue and practice using ML more often and to observe other people while working with ML to solve problems. I hope that my proficiency will continue to improve over Semester 2 as I complete more Build fortnightly homework and build a Cyber Physical System for our CPS project group which in particular will be using ML to identify the different types of e-waste using camera recognition. My desired skill level will be at least Competent to Proficient and I’m planning to achieve this level by the end of this year through building our group CPS project and learning from online tutorials such as the following:
- Google Machine Learning Crash Course. I did some part of this crash course when we learned about Fairness and Classification and I find it interesting and relative easy to follow. I would like to complete the rest of this crash course when possible so I can have a better understanding for the ML concepts and can progress my learning further to reach the Competent-Proficient level.
- Scikit-Learn Course – Machine Learning in Python Tutorial. We used the Scikit-Learn to build a ML model for the first introduction to Machine Learning homework on the last fortnight of Semester 1 and I need to understand to use this further if I want to build a ML model from the beginning for my group CPS project or other projects in the future.
Please see the chart below for an overview of my Machine Learning progress.
Introduction to Machine Learning
For the last fortnight homework, we were asked to explore each step of the supervised machine learning (ML) pipeline, from collecting a dataset to generating a model which learns from the data. The first task is to submit a reflection essay for three ML-related skills that I would like to develop throughout the ML fortnights. They are discussed on the document below.
My initial assessment of the skills related to my goals, is zero to beginner proficiency. I still don’t know exactly what is the right path to measure my growth in these skill areas, but I’m looking forward to learn more about ML in the next semester 2.
For the stretch task, I selected the second option which is the ML pipeline, because I’m fairly new to machine learning and this stretch task is recommended for the beginner so I want to learn from basic by doing this task. My 3 ML specific skills to develop are:
- Create Data Modelling by processing the classification using decision tree model on the provided datasets both Zoo and ANU coffee.
- Explain and tuning ML model, including key ML terms from each part of the ML pipeline (theoretical, practical, or both).
- Apply ML model for evaluation and quality control using the Cross-validation accuracy for training and test data.
I attempted both datasets, the Zoo and the ANU Coffee datasets, because I want to compare the difference between those two. I found the Zoo dataset gave a higher accuracy model compare to the ANU coffee dataset. Perhaps this is due to few missing data in ANU coffee and a relatively smaller dataset (<100 entries). The videos below are explaining the work I’ve done and the relevant concept of ML pipeline, including the codes in Google Collab pages.
ANU Coffee Dataset – Google Collab
Reflection
I have never done Machine Learning nor creating a Google Collab document before, so this fortnight is the busiest fortnight to date because we also have another assessment due on the same week and finalising the Maker Project before the Demo Day too. What I would do differently next time is definitely double-checking the submission link for the date and time. Also submitting it earlier and allocate enough time for video making, given I have no experience in this field and need to learn a better way to do this in future.
This homework exercise has changed my thinking around machine learning, that it’s not easy to teach the machine how to learn to produce the perfect output that human expected. It depends on the problem and the complexity of the dataset, and not everything can be solved using machine learning. Some issue can be solved better using a much more straightforward method, for example, using excel functions rather than machine learning. I overcome some of the technical challenges by working together with other cohorts (Chloe, Julian and Matt) with the help of Memunat and Matthew.
From the studio skill session from Matt and Julian, collaboration coding is another skill that I want to learn and develop in the future. I think my overall reflections have similarities, and the way I learn is by doing (give it a go) and collaborate with other people. The differences between each fortnight will be the topics and the system that I have to learn, which most of the times made me “nervouxited” (nervous and excited at the same time). Still, I always try my personal best to “freak-gure” it out (freaking out trying to figure it out at the same time).
Acknowledgement
- Sarah for being my great partner in training our NIM agent
- Maemunat and Matthew for helping us at the studio. They explain the concept and basic terminology of ML. The difference between y =f(X) as a function for example:
X = features (hair, legs, milk, etc.)
y = labels (animal names)
and the attributes where:
x = rows and y = columns
The difference between method and attribute in the command/syntax, for example:
person.name = “Matthew” → name is the attribute and it’s written without brackets
person.walk(dir=0, speed=0) →walk is the method and it’s written in brackets - Matt for explaining how to convert and upload the ANU Coffee data into the Google Collab
- Chloe and Julian for learning and working through the codes together in the studio and we shared the online tutorials and resources to help with this homework.
- James for explaining the difference data selection for training, testing and evaluating.
Modelling & Simulation
My ML journey continues on the first fortnight of Semester 2, when we were introduced to a number of simulation and modelling techniques and their role in the design of a CPS. I learned to expressing my strategy for identifying potential problems from the model. Below is my initial model-problem analysis that I draw based on my current thinking process.
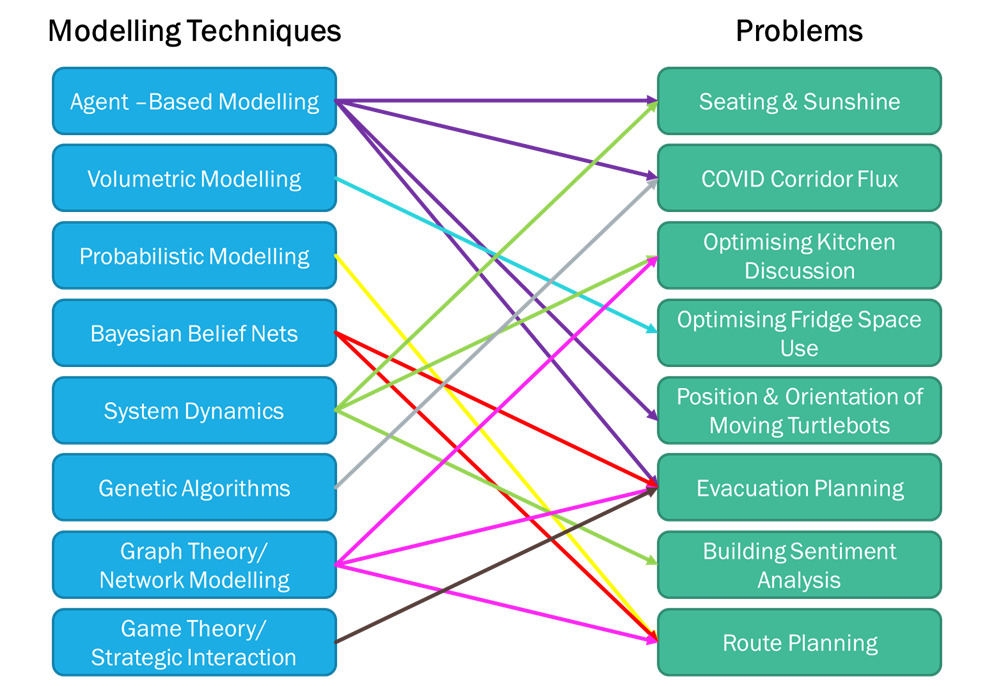
I had some basic knowledge of Agent-Based and Networking modelling techniques from my previous study, but I never used them specifically to solve problems. However, I didn’t want to limit my initial search process and stop with only those 2 models. I wanted to know and understand more about the other modelling techniques too. So I searched for all of those 8 techniques, even though in the end, I decided to choose the ABM as my model to use for problems given.
After reading more about the ABM technique applications and examples, I now think we can apply the ABM technique to many more problems than I initially thought. As Bonabeau (2002)[1] mentioned, ABM has many benefits, such as captures emergent phenomena; provides a natural description of a system; and being flexible. The ability of ABM to deal with emergent phenomena resulting from the interactions of individual entities drives the other benefits. My initial thought and final conclusion are illustrated on the diagrams below.
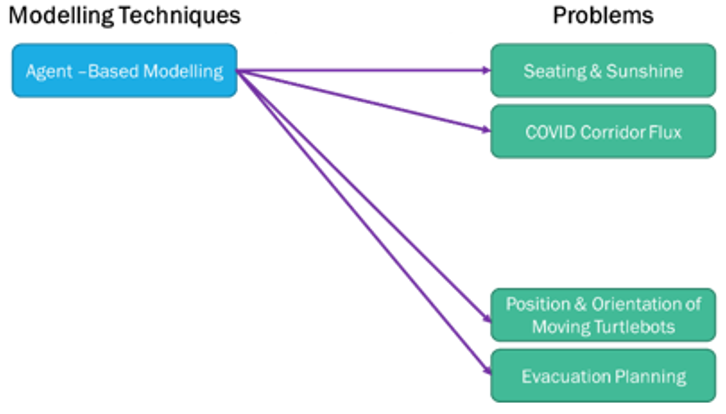
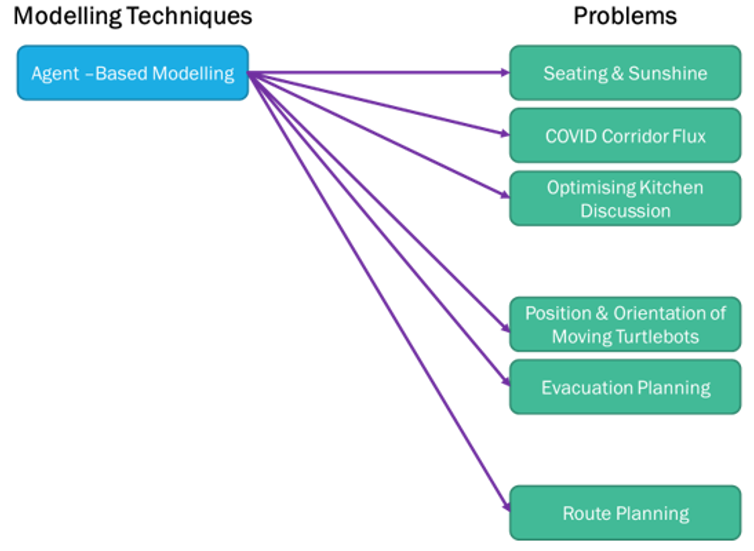
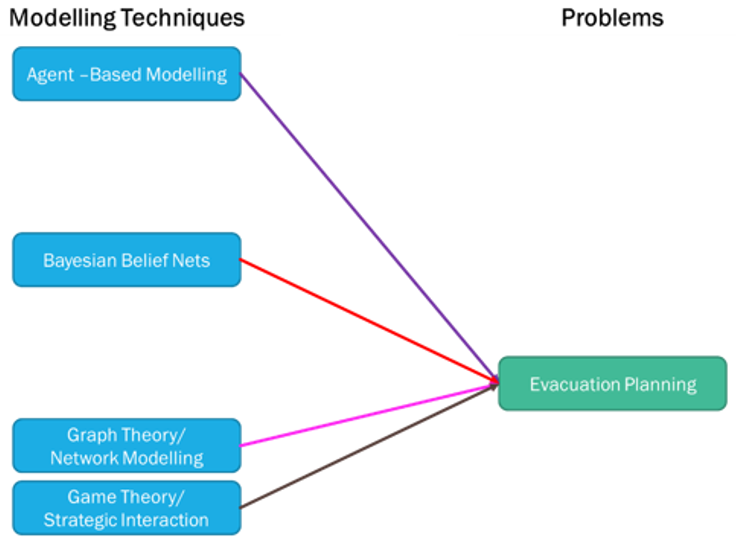
Similar finding with the modelling techniques to solve the evacuation planning problem. My initial thought has changed after I’ve done more research and listed the benefit vs limitation capabilities comparison analysis for each modelling techniques as shown on the table below.
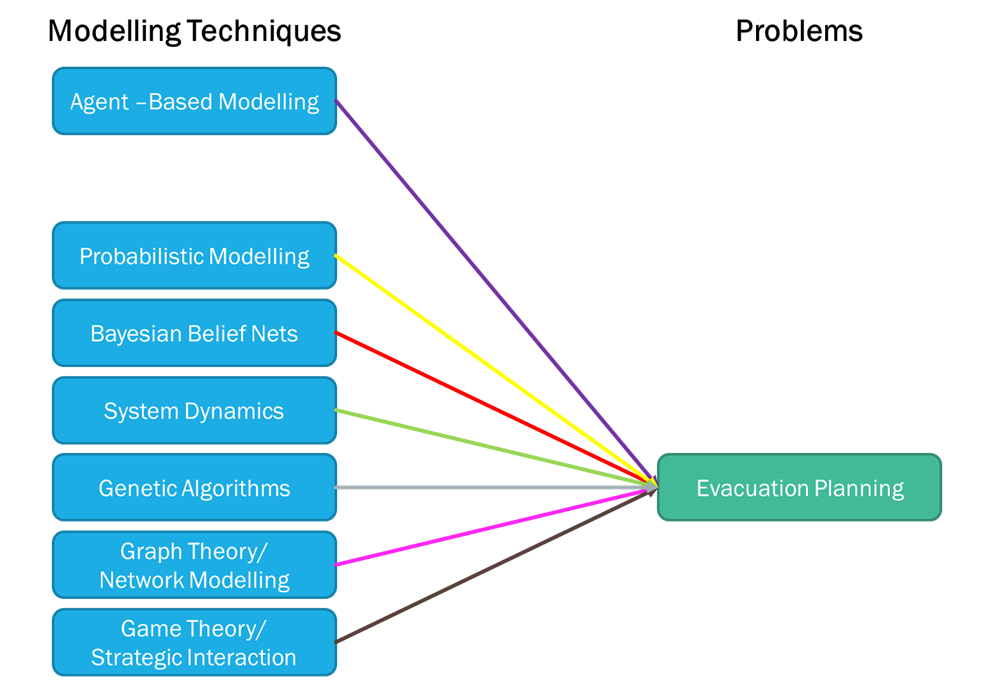
| Modelling Techniques | Good For | Limitation |
|---|---|---|
| Agent-Based Modelling (ABM) | When the interactions between the agents are complex, nonlinear, discontinuous, or discrete When space is crucial, and the agents’ positions are not fixed. When the population is heterogeneous when each individual is (potentially) different When the topology of the interactions is heterogeneous and complex. When the agents exhibit complex behaviour, including learning and adaptation. (Bonabeau, 2002)[1] | Human involvement as the agents, with potentially irrational behaviour, subjective choices, and complex psychology (the soft factors) challenging to quantify, calibrate, and sometimes justified. Need validation and verification to ensure the implemented model matches the conceptual model and relates to the real world. |
| Bayesian Belief Nets | Represent probabilistic and dynamic elements. Predicting of highly complex phenomena(Sarshar et all, 2013)[2] | Requires greater statistical expertise than some other methods It might not produce accurate results if one network loop is closed/unavailable. |
| Graph Theory / Network Modelling | Optimise the evacuation time and the number of evacuees simultaneously(Chalmet, 1982)[3] | Dependencies on the network parameters such as location, route, flow, time, especially for the large-scale network |
| Game Theory / Strategic Interaction | The competitive situation with random and rational individuals’ movement Conflicts between two or more agents that want the same position. Predict the outcomes of strategic interactions in large scales(Eng, 2016)[4] | We need to combine with another model such as ABM to get some insights into human behaviour Computationally intensive because of the trial and error Route and rules restrictions |
References
[1] Bonabeau, E., 2002. Agent-based modeling: methods and techniques for simulating human systems. Proc. Natl. Acad. Sci. Unit. States Am. 99 (Suppl. 3), 7280–7287. https://doi.org/10.1073/pnas.082080899.
[2] P. Sarshar, O. Granmo, J. Radianti and J. J. Gonzalez, “A Bayesian network model for evacuation time analysis during a ship fire,” 2013 IEEE Symposium on Computational Intelligence in Dynamic and Uncertain Environments (CIDUE), 2013, pp. 100-107, doi: 10.1109/CIDUE.2013.6595778.
[3] Chalmet, Luc & Francis, R. & Saunders, P.. (1982). Network Models for Building Evacuation. Management Science. 18. 90-113. 10.1007/BF02993491.
[4] Eng, F., 2016. Game-theoretic approaches to natural disaster evacuation modelling, PhD thesis, The University of Melbourne, http://hdl.handle.net/11343/112326
Reflection
My key learning from this homework is good to explore more information to understand and learn more new things and enhance what I already know further. But sometimes, too much information could make me overwhelmed too. So, I need to be more strategic and systematic in my research. Initially, I struggled to visualise my search mapping until Kate shares the article on visualising your browser history for Google Chrome, and that’s how I draw the connections for each modelling technique. More importantly, this homework has changed how I search information online going forward, especially when I have specific goals that I want to find out, not just browsing for fun. I also learned from my initial search where the agent-based model can be used to solve some of the problems given, but after going through all the tasks, I realised that this model could be used for a few more problems that I didn’t think could before. For example, after playing with some modelling examples in NetLogo, the flocking modelling (Wilensky, 1998) could be seen as part of the agent-based modelling technique because it has interactions between agents and flows as described by Bonabeau (2002). From finding the models benefit and limitations, my initial assumption of the model to solve the evacuation problem has changed too. A lot more models can be used to solve the evacuation planning problem. It all depends on the circumstances, what kind of emergency, the size of people needs to be evacuated, the location, magnitude of catastrophic, etc. Understanding the modelling technique and problem relationship is good learning for me this fortnight, but my reflection is more around how do I search academically, which could be good if I want to pursue any research pathway such as doing a PhD in future.
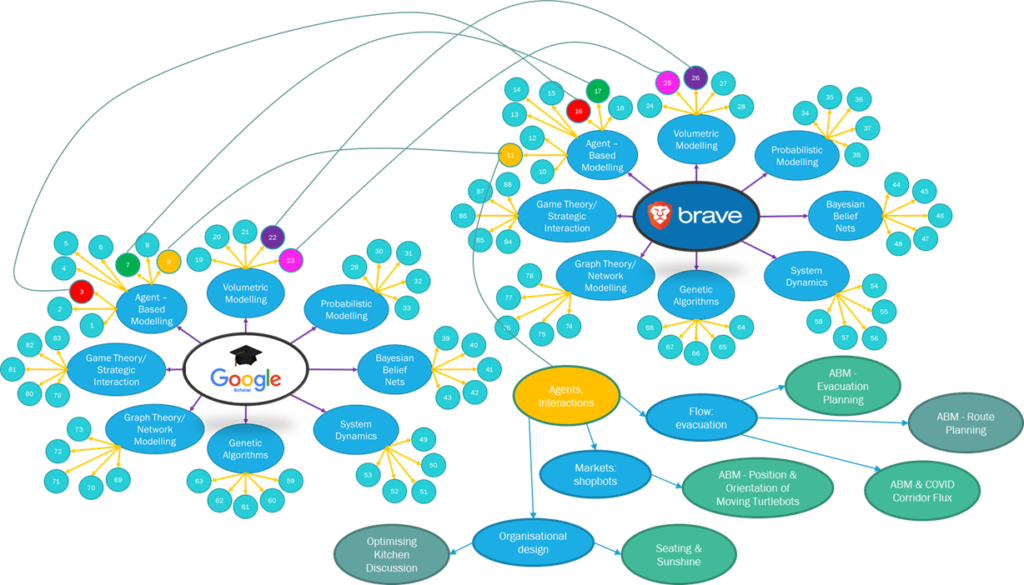
Acknowledgements
- Matthew & Mina explanation during the session has helped me to understand a bit more around the modelling techniques with some examples and especially with the recent activities in class using NetLogo.
- Julian & Adrian who shared their understanding of the modelling techniques and problems during our CPS project chats.
- Kate for sharing her finding in Visual History for Google Chrome.
- Matt for briefly explaining about how search engine works and mentioned a new term that I never heard before “Google Dorking”
ML and Fairness
On the 2nd fortnight we explored the role of bias in Machine Learning, and common indicators for fairness in the ML pipeline as ways of assessing a model’s behaviour, and how we look at the role of performance and fairness measures in evaluating a model. Using the lens of ML fairness, we also explored problem formulation and model validation in the ML pipeline. I learned the different types of bias, how to identify bias and how to evaluate for bias through the Google Machine Learning Crash Course for topic Fairness. I’m interested in knowing how fairness in ML can be identified from different types of bias in a model and how to measure a model performance using a confusion matrix.
I didn’t choose the stretch task based on my current skill level, which most likely sits around 1-2 chillies. And I know streth-task#3 has 3 chillies which mean more complex than the 2 chillies stretch task# 2 (Analysing a model for fairness with the ‘What If Tool‘). But the opportunity to work on Google Colab using TensorFlow and Confusion Matrix excites me more because I really enjoyed the S1 HW6 on Zoo/ANU Coffee dataset, where I learned about ML and using Google Colab for the first time. The challenges that I had in completing that homework have shaped my learning goals to explore and understand other ML skills using tools such as Facet, Pandas, and Numpy. I always believe that I will learn more when I’m being challenged, and hopefully, this can enhance my skills in the future, especially in ML.
TensorFlow is something that I heard before, but I don’t know how it works, so I would like to find out and learn more by using it in this stretch task #3 Intro to Fairness in ML with TensorFlow. I think learning how to use TensorFlow can help me advance my ML skill, especially when my CPS project team is planning to build/make a CPS that will use ML to recognise the type of electronics for our e-waste “bin”.
After going through the Colab Notebook exercises, especially the FairAware tasks, I learned how to use Facets Overview and Dive, which helped us visualise and understand the relationship of the data. My comment and reflection can be found in my Colab Notebook. My key take-away from this homework is how to balance the performance metrics such as accuracy, precision, recall, and n trade-offs between the FP, FN, TP, TN. Weighing the cost of FP and FN is a critical decision that affects someone’s life/experience.
Before I learned about the confusion matrix, I always thought that model with a high-performance score is the best; but now I know it’s not always the case if it’s an overfitting model or not having sufficient data, under-representation, and many other forms of biases that could affect the
result. Also, from FairAware Task #4, I learned that it’s essential to analyse the subgroup as well as the aggregate level to investigate any biases deeper. The better we know our data, the more insight we’ll have on whether there’s any unfairness in our data. Through the confusion matrix exercises, I also learned how model performance depends on the goal and purpose of the model, and of course, the intended use for who we’ll be using the model for.
Reflection
The key lessons that I learned from attempting this stretch task are definitely around bias and how we often tend to have prejudice whether we are aware of it or not. More importantly, the unintended consequences that we learned in the S1 Framing Question can happen due to bias (e.g., gender, race, etc.). This can often be dangerous and could affect someone’s life, future, well-being, and happiness, such as the life sentence in court, job hiring process, life insurance/home loan approval, etc. Through the confusion matrix exercises, I also learned how model performance depends on the goal and purpose of the model, and of course, the intended use for who we’ll be using the model for.
The People + AI guidebook taught me about trade-offs between the FP, FN, TP, TN. Weighing the cost of FP and FN is a critical decision that affects someone’s life/experience. By default, I tend to weigh both equally. However, that’s not likely what happens in a real-life situation.
For example, in the case of a fire in the house, having an alarm that doesn’t go off is more dangerous than having a false alarm, even though both are incorrect. So False Negative (FN), in this case, is more hazardous than False Positive (FP). On the other hand, if my Netflix recommends movies that I don’t like, I can just watch another movie, not as dangerous as the fire alarm example. But I also need to make sure that I have the right balance between precision & recall (also considering the Error Rate) numbers that are right for the model’s intended use. For example, optimising the precision can reduce the number of FP but may
increase FN. On the other hand, optimising the recall will show more TP but also increases the number of FP. So, it depends on the problems that I try to model and, more importantly, the intended use of this model.
I think it’s also essential to identify whether ML is the proper method to use (or not) to solve the specific problem.
I learned from Simulation & Modelling that no single modelling technique is perfect for solving all ML problems. And that we should consider using a variety of approaches to iterate and improve the model to ensure fairness for everyone. This fortnight homework has significantly changed my thinking and practice from now on, especially in ML. I will try to design the model with fairness and inclusion goals in mind. Consciously use more representative datasets to train and test my model, constantly check and analyse the system performance on my model to avoid any biases as much as possible, more aware of the trade-offs possibilities and challenges, because I believe this skill is critical to have as an NBE practitioner.
Teachable Machine
Overall, I believe I have progressed from zero skills in Machine Learning. Based on my learning experiments and experiences in Semester 1 and 2, I think I am now sitting at the Competent level on the Dreyfus Model. I hope to continue developing my skills in Machine Learning to become Proficient or even Expert in the future after finishing he Masters program and have the opportunity to apply this skill at work.